By default Django renders templates from disk on each request, which means if you edit a template file the changes will be reflected instantly on the site. That’s intuitive and all, but since code is kept in memory and thus code changes are not reflected until server processes are restarted, it’s easy to get yourself out of sync. I recently deployed a code/template change that depended on each other (the existing templates were incompatible with the new code) and between the time Mercurial synced files and the Apache processes were restarted I received dozens of emails about 500 errors. It was only a couple of seconds and I could not have done it any faster, but at the end of the day seeing dozens of errors is unacceptable.
Enter, django.template.loaders.cached.Loader. It’s a template loader introduced in Django 1.2 that keeps template files in memory. I’m not sure how I missed this until now. Using the cached loader will increase your memory footprint a bit, but it will keep them in sync with the code so all your changes deploy at the same time. If you have a lot of templates the memory footprint may be more significant, but it was very minor in my case.
To use it you wrap django.template.loaders.cached.Loader with the other template loaders you want it to cache. Since I wasn’t doing anything unusual I was able to get away with it wrapping the default loaders like so in settings.py:
TEMPLATE_LOADERS = (
('django.template.loaders.cached.Loader', (
'django.template.loaders.filesystem.Loader',
'django.template.loaders.app_directories.Loader',
)),
)
With that one change I can now deploy code and template changes and have them reflect at the same time. I am not sure why this isn’t the default, having your code update separately from your templates is illogical. Keeping it all in sync seems like common sense.
This change can be somewhat annoying while using the development web server since it automatically reloads when you change code but not when you change templates. To get around this you can either set TEMPLATE_LOADERS differently based on the value of DEBUG or override TEMPLATE_LOADERS in your local settings file(s) (assuming you have one). I’m overriding and it works fine.
This is more for me in the future, but it’s public just in case anyone else has the same question. I have a KitchenAid Artisan Series 5-Quart Mixer (it’s great, I’ve had mine since 2007) and often bake with a digital scale. On multiple occasions I have wanted to subtract the weight of the mixing bowl, but only deciding this after adding things to it and forgetting to notate its starting weight or taring the scale. It’s a pain to figure this out after the fact and I had previously managed to not write down its weight. So for me and whoever else, here it is:
The weight of KitchenAid’s standard 5-quart mixing bowl is 793 grams (28 ounces)
 I have a rooftop garden in downtown Tampa and thanks to the lack of an outside spigot have to manually transport water from inside. Well had to, now there’s a rain barrel that is fed by the AC unit. Being in humid Florida and for cooling a couple thousand square feet, the unit puts out a lot of water per day (at least five gallons) and was previously emptying onto the roof and simply going down the drain.
I have a rooftop garden in downtown Tampa and thanks to the lack of an outside spigot have to manually transport water from inside. Well had to, now there’s a rain barrel that is fed by the AC unit. Being in humid Florida and for cooling a couple thousand square feet, the unit puts out a lot of water per day (at least five gallons) and was previously emptying onto the roof and simply going down the drain.
I searched Amazon for a rain barrel and got a model from Algreen. After it was delivered I went to Home Depot and bought 3/8″ tubing and a 3/8″ hose barb splicer to connect the existing tubing and my extension. The rain barrel I bought (like almost all) is meant to tap into a gutter system, but has spaces to drill holes for tubing to connect multiple barrels together and/or for diversion when the barrel is full. I drilled a 3/8″ hole in one of these and inserted the extended AC drain tube and drilled out the other to divert into the drain. The photo is after the first portion, the hose shown is coming from the AC that is on the building’s roof. The building has 10′ ceilings and about a 4′ crawl space above that, but there’s a half height portion where the door out to the deck is and that’s what the barrel is on. It’s convenient in that the water is coming from basically a story above the barrel and the barrel is feeding a garden about a story below–gravity is easy to harness.
It almost immediately started to fill with water and so far is providing more water than I need for the garden (time to get new plants!). It has not filled completely yet so I haven’t had time to perfect the overflow. For now it’s just a hose out and into a drain.
This is a great way to use a rain barrel for when you don’t have a gutter system in place or don’t want to use water that has been exposed to your roof. For the most part we have a flat commercial roof without gutters, not to mention all the tar and associated materials that roofs contain. This clean water was previously being thrown away. I’ll have to figure something out in the winter when the AC is not running, but for now it has the added benefit that it generates the most water on the hottest days which is exactly when the garden needs the most water. It’s a simple hack and took remarkably little time. The barrel itself even shipped overnight with Amazon Prime so the most time consuming process was probably hunting around Home Depot.

Since 2004 I have provided a mobile optimized version of the Drudge Report. I was a bit early on the mobile curve and back in 2004 browsers weren’t nearly as sophisticated (or data access as fast), so it was a huge time saver. Even today having one column makes things a ton faster to read, so it has continued to draw an audience.
After some slowdowns on my server I noticed a very large amount of iPhone users (north of 100,000 unique monthly) using the site, which I thought strange because on my other sites mobile usage is pretty evenly split across lines according to market share. There were no referrers, so I had no further insight into where the traffic was coming from. I updated it to use memcached which helped reduce load on my server and then didn’t put a whole lot of thought into it other than fixing it when Matt would change his formatting a bit and a user would email me letting me know (I rarely if ever use it myself).
Flash forward to this week when in the comments of a post on Hacker News I mentioned this mysteriously popular web service and measure2xcut1x piped in saying they have an iPhone app for the Drudge Report that uses my URL. It all clicked–that explains iOS traffic dwarfing all other mobile OS’s and the lack of referrers. I quickly got the app name and downloaded both the free and paid ($.99 at the time of download) versions to confirm. Sure enough, the app is a webkit view around my site with either iAds or the $.99 purchase price. All the while I’m funding the millions of hits monthly that the site receives. I was happy to provide free hosting/reformatting as a sort of public service, but not happy that someone else was profiting off it.
I emailed the app’s listed developer, James Leung of Smartest Apple and asked to talk. After some back and forth (and disagreements) I ended up shutting the app down by changing the URL of the service, 301 redirecting anyone not on an iPhone and providing a note for iPhone users telling them of the situation. Drudge’s humorous siren graphic was also used, which made it pretty apparent something was wrong. This didn’t endear me to James much (or his superiors who control the money), but since I knew an update to the app to cut me out was coming ASAP and I had limited time with leverage.
I then had an idea, instead of sending me the money it could instead be donated to charity. With the current earthquake/tsunami/nuclear situation in Japan this seemed like a perfect idea and while I could find many ways to waste the money, the Red Cross could actually put it to good use. James wrote back right away saying he was in for his (small) cut of the revenue, but would have to get back to me for the bulk of it from his company. He wrote back again quickly saying that his employers would donate $5,000 if I would immediately return the functionality of my site so the app continued to work (negative reviews were pouring in). Almost directly afterwards I got another reply saying a matching $5,000 donation would also be made by the parent company. $10,000 to the Red Cross for Japan relief isn’t something to sneeze at, so I returned full functionality and thanked them for their generous donation. This morning he posted a video on YouTube of the first $5,000 donation while the matching donation is still in progress (at the end it says on behalf of 715 Franklin, which is the shared office I’m a part of in Tampa).
Considering how my first thoughts of what to do were incredibly immature (goatse?), I’m very happy of how this turned out.
tl;dr a couple days after a Hacker News comment I was able to help secure $10,000 for the Red Cross. The Smartest Apple and James deserve credit for turning around a bad situation into a big win for people in need.
Now that Google has an official extension to block domains from search engine results, I thought it would be handy to list the largest and most prevalent content farms. Google’s Personal Blocklist works well, but doesn’t let you access a shared block list so it’s up to you to have a good list. It also makes you add sites from Google search result pages, so you’ll have to search for these domains and use the new block links that get injected by the extension. It’s a few more hoops to jump through than I’d like, but well worth it for less spammy SERPs going forward.
Update: Google has now made this an official feature of their web search, so there’s no longer a Chrome extension required. It’s a bit more of a hassle to block sites with, but having cross browser support is a big win (I was already bugging out seeing spam results in my mobile searches).
Update on March 23rd 2013: Google has removed the Blocked Sites feature and is suggesting everyone use the extension. The list below should still be a good starting place.
List of content farms and general spammy user generated content sites:
Note: The links go to a Google search for the associated domain, which lets you easily add it to your block list.
Further note: while it should go without saying, the below list of content farms is entirely of my own opinion. If you disagree, don’t block them (and feel free to comment and tell me why).
I’ll keep this list updated as I go. Please leave a comment if you see any I missed.
I upgraded Crossword Tracker to use jQuery Mobile at the end of November and while it has proven popular, I had a sneaking suspicion my Google Analytics reports were off. The Pages/Visit statistic was quite low (very close to 1 in fact). It turns out that jQuery Mobile requires a little extra effort to execute Javascript on every page load. I broke up the Analytics code into two pieces and now every page view is being tracked.
In the head (which is executed only on the first page load) I load the required Javascript file from Google, using the async loader which means it won’t block page loading:
<script type="text/javascript">
var _gaq = _gaq || [];
(function() {
var ga = document.createElement('script'); ga.type = 'text/javascript'; ga.async = true;
ga.src = ('https:' == document.location.protocol ? 'https://ssl' : 'http://www') + '.google-analytics.com/ga.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ga, s);
})();
</script>
Originally I had the whole snippet from Google there and it counted just one view, no matter how many pages the user actually viewed. That’s because it’s not actually loading the whole other page, but requesting it with AJAX and then replacing parts of the page with new content. The trick to getting all page views counted is splitting up the part that tracks the page view. Here’s what I tucked in before the closing body tag:
$('[data-role=page]').live('pageshow', function (event, ui) {
try {
_gaq.push(['_setAccount', 'YOUR_GA_ID']);
hash = location.hash;
if (hash) {
_gaq.push(['_trackPageview', hash.substr(1)]);
} else {
_gaq.push(['_trackPageview']);
}
} catch(err) {
}
});
The pageshow event is triggered by jQuery Mobile on every page load (including the first), so we’re now calling the _trackPageview() method on every load. Handy. After just a day and a half’s worth of use, you can tell what a difference it made:
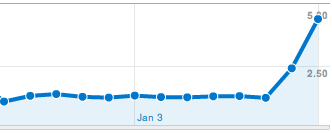
This all may change before jQuery Mobile hits 1.0, but for now I’m safely on the bleeding edge and have the analytics to back it up.
Update: jQuery Mobile falls back to using hashes to designate pages and that doesn’t get picked up by GA so / and /#/contact would both appear to be a hit on the homepage. You can easily get around this by checking for the hash and then sending the portion after the # symbol. I have updated the code above to account for this as well as moving to the asynchronous loader which makes a decent difference over 3G.
Update 2: I’m no longer using jQuery Mobile on Crossword Tracker because the way it works conflicts with Google Adsense. Mobile traffic has been steadily increasing and now makes up close to 50% of Crossword Tracker’s traffic.
A while back Brighthouse (who markets their cable modem service under the Road Runner brand) decided to drum up some revenue by redirecting unresolved DNS requests to a search results page loaded with a bunch of ads. This means if you make a typo instead of an error you get a search page that looks like a lot of the scammy domain parking pages that fuel the domain squatting industry. The search results are powered by Yahoo, which these days means Bing. The PPC ads take up most of the focus area of the page and are disguised to look like organic search results. tl;dr scammy
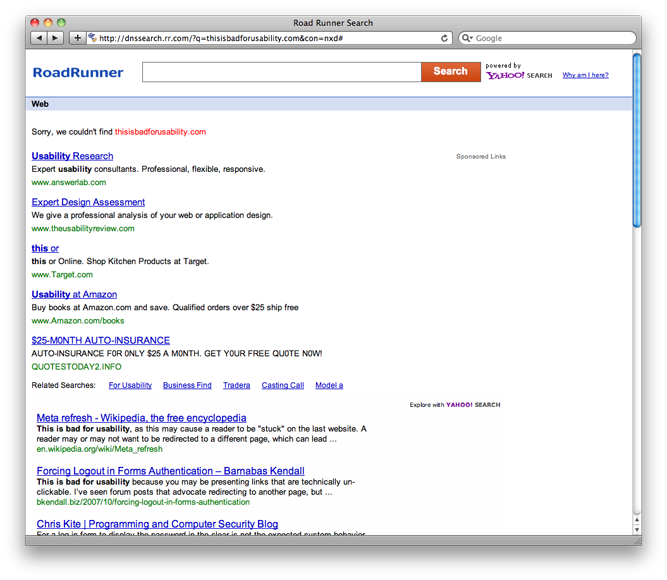
There’s supposed to be a way to opt-out, but at some point in time it broke. I had opted out a while back, so was surprised to see this page again. I checked the setting and sure enough I was still opted out. It’s pretty dick to hijack DNS resolving and then lie about opting out your users who have gone out of their way to do so.

Getting rid of it for real is simple, stop using your ISP for DNS. If Brighthouse or Time Warner can’t be trusted to honor their own opt-out preferences, don’t bother giving them the chance. I switched to Google’s Public DNS as it’s fast and completely ad-free like DNS should be. OpenDNS is popular, but by default does a similar redirect (though they honor your opt-out).
In honor of Firesheep’s release, I whipped up an AppleScript that goes through the steps to have your Mac use a SOCKS proxy (AKA SSH tunnel). For the unfamiliar, this is a technique that involves creating an encrypted connection to a server you have access to and then redirecting all your network traffic through it. It’s wise to use such a setup when on an untrusted network connection, such as any open wireless network (note that Firesheep only works on an open wireless network). This tutorial assumes you already have access to a server with OpenSSH installed, preferably with key-based authentication so passwords don’t need to be exchanged.
The standard way to setup a SOCKS proxy is opening Terminal.app and running ssh with a couple extra flags. This will initiate a SOCKS proxy over the port 8888:
ssh -vND 8888 user@host.com
I run SSH on a non-standard port, so I also tack on -p X before user@host where X is the port SSH runs on. To make things a little easier, I aliased this in my .profile:
alias socks="ssh -vND 8888 -p X user@host.com"
Now I just have to type “socks” in a Terminal window and I’m all set up. To make your Mac actually use the proxy involves going into System Preferences > Network > Advanced… > Proxies and checking off the SOCKS Proxy checkbox. Make sure your port agrees with whatever you used to start the tunnel and after saving your changes you should be good to go. FireFox doesn’t use a proxy for DNS requests by default, but you can change that by going to about:config and toggling network.proxy.socks_remote_dns to true. After you’re set up, go to a site like whatismyip.com and make sure your IP is originating from wherever your SSH server is from (in my case Slicehost).
The process of going into System Preferences can be a bit of a drag, so I customized an AppleScript to do it for me. This script will toggle the status and announce what the result is.
Read more
Who is writing error messages these days at Adobe? Pathetic. Even better was this message was just so I would know that CS5 was going to crash and there was nothing I could do. Thanks guys.
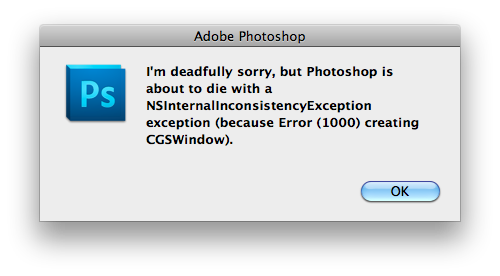
“I’m deadfully sorry, but Photoshop is about to die with a NSInternalInconsistencyException exception (because Error (1000) creating CGSWindow).”
I needed to set up an automated backup of a Postgresql database on an Ubuntu Server 10.04 box and it took more Googling than should be necessary. I wanted to keep nightly snapshots for the past week which makes it a tiny bit more difficult than simply running pg_dump from a crontab. Here’s the one liner shell script I ended up with:
#!/bin/bash
pg_dump -U DBUSERNAME -b -F c -f "/path/to/backups/postgresql/`date +%w`.backup" MYDBNAME
Make sure to setup your .pgpass file if you haven’t already. Test it on the command line and if it’s all good just add it to your crontab file. I have mine running every morning at 2AM.

{kind=link}